╚ńĮ±Ż¼AIįńęčĮøū▀▀M┴╦╬ęéā╔·╗ŅŻ¼╬─ą─ę╗čįĪó═©┴xŪ¦å¢ĪóČ╣░³Īó▀ĆėąūŅĮ³ĘŪ│Ż╗▒¼Ą─DeepSeekĄ╚┤¾─Żą═ūī╚╦éāęŌūRAI▓ó▓╗╩Ū─Ū├┤╔±├žŻ¼▀@└’Ż¼╬ęéāė├RAGŠ═┐╔ęįūį╝║┤ŅĮ©ę╗éĆPGŽ“┴┐öĄō■ÄņAIÖCŲ„╚╦ĪŻ
RAGĖ┼─Ņ
RAG(Retrieval Augmented Generation)ŅÖ├¹╦╝┴xŻ¼═©▀^Öz╦„Ą─ĘĮĘ©üĒį÷ÅŖ╔·│╔─Żą═Ą──▄┴”ĪŻ
Öz╦„(Retrieval ): Ė∙ō■ė├涚łŪ¾Å─═Ō▓┐ų¬ūRį┤Öz╦„ŽÓĻP╔ŽŽ┬╬─ĪŻ
į÷ÅŖ(Augment): ė├æ¶▓ķįā║═Öz╦„ĄĮĄ─ĖĮ╝ė╔ŽŽ┬╬─▒╗╠Ņ│õĄĮ╠ß╩Š─Ż░ÕųąĪŻ
╔·│╔(Generate): Öz╦„į÷ÅŖ╠ß╩Š▒╗ü╦═ĄĮ LLMĪŻ
╦³╩Ūę╗éĆ×ķ┤¾─Żą═╠ß╣®═Ō▓┐ų¬ūRį┤Ą─Ė┼─ŅŻ¼▀@╩╣╦³éā─▄ē“╔·│╔£╩┤_ŪęĘ¹║Ž╔ŽŽ┬╬─Ą─┤░ĖŻ¼═¼Ģr─▄ē“£p╔┘─Żą═╗├ėXĪŻ
╩╣ė├RAGĄ─ā׳c
╠ßĖ▀£╩┤_ąį: ═©▀^Öz╦„ŽÓĻPĄ─ą┼ŽóŻ¼RAG┐╔ęį╠ßĖ▀╔·│╔╬─▒ŠĄ─£╩┤_ąįĪŻ
£p╔┘ė¢ŠÜ│╔▒ŠŻ║┼cąĶę¬┤¾┴┐öĄō■üĒė¢ŠÜĄ─┤¾ą═╔·│╔─Żą═ŽÓ▒╚Ż¼RAG┐╔ęį═©▀^Öz╦„ÖCųŲüĒ£p╔┘╦∙ąĶĄ─ė¢ŠÜöĄō■┴┐Ż¼Å─Č°ĮĄĄ═ė¢ŠÜ│╔▒ŠĪŻ
▀mæ¬ąįÅŖŻ║RAG─Żą═┐╔ęį▀mæ¬ą┬Ą─╗“▓╗öÓūā╗»Ą─öĄō■ĪŻė╔ė┌╦³éā─▄ē“Öz╦„ūŅą┬Ą─ą┼ŽóŻ¼ę“┤╦į┌ą┬öĄō■║═╩┬╝■│÷¼FĢrŻ¼╦³éā─▄ē“┐ņ╦┘▀mæ¬▓ó╔·│╔ŽÓĻPĄ─╬─▒ŠĪŻ
RAGŽĄĮy╣żū„┴„│╠łDĮŌ
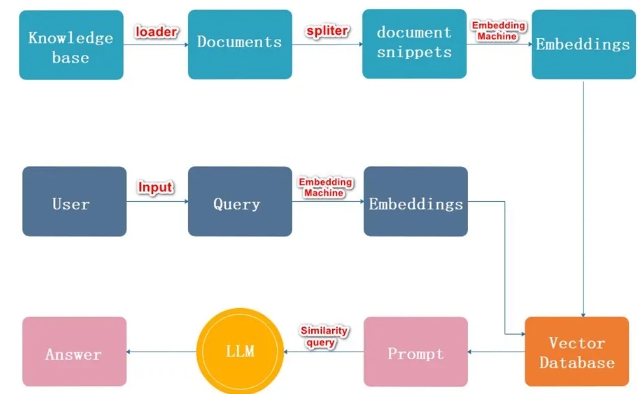
┴„│╠├Ķ╩÷Ż║
1. ╝ė▌dŻ¼ūx╚Ī╬─Ön
2. ╬─ÖnĘųĖŅ
3. ╬─ÖnŽ“┴┐╗»
4. ė├æ¶▌ö╚ļā╚╚▌
5. ā╚╚▌Ž“┴┐╗»
6. ╬─▒ŠŽ“┴┐ųąŲź┼õ│÷┼c墊õŽ“┴┐ŽÓ╦ŲĄ─ top_k éĆ
7. Ųź┼õ│÷Ą─╬─▒Šū„×ķ╔ŽŽ┬╬─║═å¢Ņ}ę╗Ų╠Ē╝ėĄĮ prompt ųą
8.╠ßĮ╗Įo LLM ╔·│╔┤░Ė
......
═Ļš¹╬─Önµ£ĮėŻ║
╬─ÖnŻ║RAG-┤¾─Żą═&Ž“┴┐öĄō■Äņ.pdf
ŠW▒Pµ£Įė:
https://pan.baidu.com/s/1b4yXjlyw2uF7K-iOSnpGYQ
╠ß╚Ī┤a: qanz
BšŠį┌ŠĆęĢŅlŻ║
https://www.bilibili.com/video/BV1WsNZe6EVp/
į¬Ž³╠ž╗▌!
į¬Ž³╝č╣ØŻ¼CUUG×ķ─·½I╔Ž║├ČY!
┘Å┘Ią┼äōPostgreSQL╣▄└ĒåTšJūCšn│╠Ż¼┘ø╦═PGCP║═PGCMę╗┤╬ča┐╝ÖCĢ■Ż¼╗Ņäė▀Ćėą7╠ņŻ¼ĪŠķåūxįŁ╬─Ī┐┬ōŽĄ┐═Ę■ł¾├¹!
